
MLLib提供了一系列基本数据类型以支持底层的机器学习算法。主要的数据类型包括:本地向量、标注点(Labeled Point)、本地矩阵、分布式矩阵等。单机模式存储的本地向量与矩阵,以及基于一个或多个RDD的分布式矩阵。其中本地向量与本地矩阵作为公共接口提供简单数据模型,底层的线性代数操作由Breeze库和jblas库提供。标注点类型用来表示监督学习(Supervised Learning)中的一个训练样本。
Spark入门 第六章 第一节 Spark - MLib简介
机器学习可以看做是一门人工智能的科学,该领域的主要研究对象是人工智能。机器学习利用数据或以往的经验,以此优化计算机程序的性能标准。一种经常引用的英文定义是:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E。
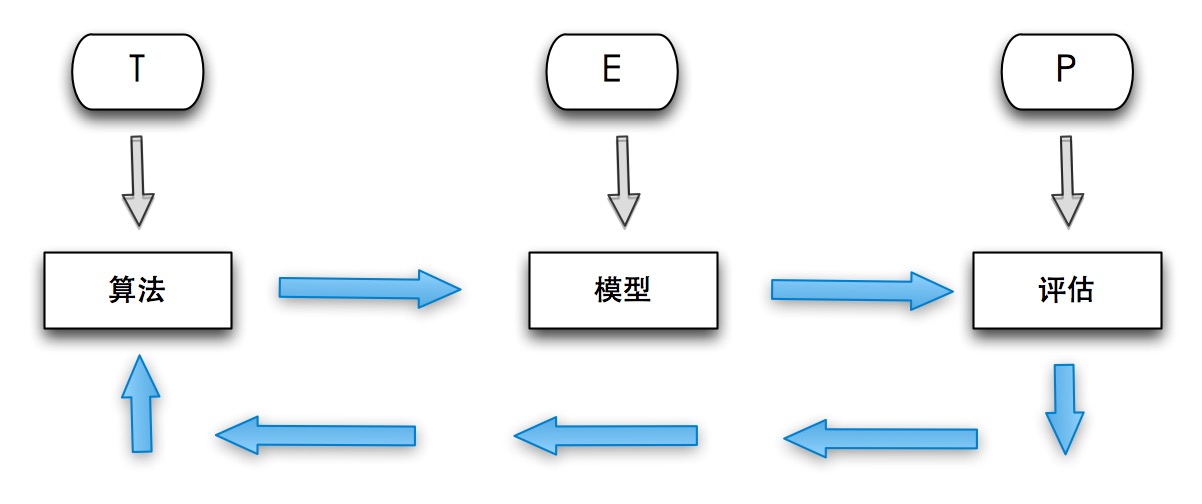
机器学习
Http常见状态码
西红柿鸡蛋面
鸡蛋面做法小计
今天天气阴沉沉的,但丝毫没有影响到我的心情,因为从某东上买的铁锅到了,于是马不停蹄地跑到附近的菜市场买了点生猪肉准备炼锅(炼锅教程可查看我的另一篇博客)。
炼完锅后于是就准备做一个番茄鸡蛋面来打打牙祭。因为,之前吃过女友做的,味道的确很好,于是这次准备亲自下厨,尝尝自己的手艺。接下来就把自己做的过程记录一下。
Spark入门 第五章 第四节 Spark - Spark 文件流(Dstream)
Spark支持从兼容HDFS API的文件系统中读取数据,创建数据流。