
Spark SQL可以支持Parquet、JSON、Hive等数据源,并且可以通过JDBC连接外部数据源。前面的介绍中,我们已经涉及到了JSON、文本格式的加载,这里不再赘述。这里介绍Parquet,下一节会介绍JDBC数据库连接。
Spark入门 第四章 第四节 Spark - 从RDD转换得到DataFrame
Spark官网提供了两种方法来实现从RDD转换得到DataFrame,第一种方法是,利用反射来推断包含特定类型对象的RDD的schema;第二种方法是,使用编程接口,构造一个schema并将其应用在已知的RDD上。
Spark入门 第四章 第三节 Spark - DataFrame的创建
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能。
Spark入门 第四章 第二节 Spark DataFrame与RDD的区别
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。
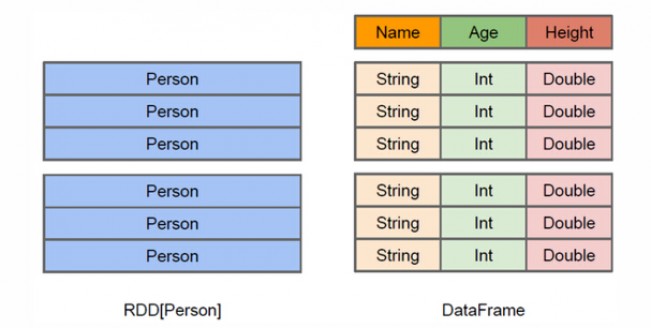
图 DataFrame与RDD的区别
Spark入门 第四章 第一节 Spark SQL简介
Spark SQL是Spark生态系统中非常重要的组件,其前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目于2014年开始停止开发,转向Spark SQL。Spark SQL全面继承了Shark,并进行了优化。